Denne artikkelen er produsert og finansiert av Universitetet i Oslo - les mer.
Den tydeligste trenden siden 2010 innen fagområdet fysikkutdanning er hvordan studenter lærer når de jobber i grupper og hvordan de utvikler en fagperson-identitet.(Illustrasjonsfoto: UiO)
Kunstig intelligens avslører hva som er trendy i forskning
Forskerne lar algoritmer finne ut hva vitenskapelige tekster handler om.
Hvordan holder forskere seg oppdatert på et fagfelt når det publiseres hundrevis av vitenskapelige artikler hvert år?
Forskere baserer seg på anbefalinger fra kolleger, nyhetsbrev og Google Scholar, en slags Facebook for forskning.
Nå mener forskere at det kanskje finnes det kraftigere metoder for å få hjelp til gjennomgangen av litteraturen på et område.
Søkte i artikler om fysikkutdanning
– Det begynte egentlig med at vi trengte å lære oss mer praktisk bruk av maskinlæring, en gren av kunstig intelligens, forteller Tor Ole Odden, postdoktor ved Center for Computing in Science Education (CCSE) på Universitetet i Oslo (UiO).
– Ganske raskt fikk vi interessante funn, sier han.
Sammen med kollegene Alessandro Marin og Danny Caballero tok han i bruk en maskinlæringsteknikk innen automatisert analyse av tekster.
De lot et dataprogram jobbe med 1300 vitenskapelige artikler om forskning på fysikkutdanning, publisert siden 2001.
Tor Ole Odden og Alessandro Marin har brukt maskinlæringsteknikk for analyse av ulike tekster.(Foto: Hilde Lynnebakken / UiO)
2000-tallet: Hva skjer i studentenes hoder?
– Vi så en del tydelige trender i hva det forskes på, sier Odden.
– På tidlig 2000-tall var forskerne i fagfeltet vårt opptatt av det kognitive, hva som skjer i studentenes hode når de lærer fysikk, forteller han.
Rundt 2010 var fokuset skiftet til å se på problemløsning og hvilke strategier studentene tar i bruk.
Den aller tydeligste trenden de fant er denne: Siden 2010 har forskningen gått fra å se på hva som skjer i hver enkelt students hode til å undersøke hvordan de jobber sammen i grupper og hvordan de skaper seg en identitet som fysiker.
Trendene endrer seg
Trenden har nådd UiO også. Prosjektet Interactive engagement and motivation in physics learning studerer blant annet studentenes utvikling av en såkalt faglig identitet – hvordan de ser på seg selv som en fagperson.
– Vi finner også igjen dette sosiokulturelle perspektivet i måten vi tenker om utdanning, sier Odden.
På UiO har ikke fysikkstudentene noen fysikkemner første semester. De lærer matematikk, informatikk og programmering.
– Flere blant lærerstaben uttrykker bekymring for hvordan studentene skal utvikle sin identitet som fysiker, og universitetet innfører tiltak for å bøte på dette, påpeker han.
Annonse
Hva har endret seg på 100 år?
Odden og Marin er i gang med en større analyse, over 5000 artikler publisert i tidsskriftet Science education de siste 100 årene.
Med seg på laget har de historikeren John Rudolph ved University of Wisconsin.
– Gjennom våre analyser kan vi finne hvilke temaer som studeres. Med hans hjelp håper vi å finne ut om disse trendene har noen sammenheng med historiske hendelser, sier Odden.
Forskerne kan for eksempel se fra analysene at det har vært en stor økning i forskning på kjønnsskjevheter innenfor naturfag og rekruttering av vitenskapelige forskere i de siste 50 årene, med store bølger av interesse midt på 80-tallet og de siste 15 årene.
– Vi tror disse bølgene muligens henger sammen med noen store amerikanske rapporter, som The Nation at Risk på 80-tallet og The Opportunity Equation i 2009, som påpekte problemer med kjønnsskjevhet, forteller han.
Han håper å få svar på hvor annerledes måten vi underviser på nå er sammenlignet med for hundre år siden.
Tidligere la undervisere større vekt på å bruke eksempler fra hverdagen.
– Uten lett tilgjengelige Youtube-filmer og animasjoner var det nødvendig å ty til enkle midler, sier Odden.
– Vi hører stadig at studentene må bli mer aktive. Det ser ut til at hver generasjon undervisere må finne opp sin egen variant av dette. Kanskje kan vi avsløre flere slike gjentakelser og slippe å finne opp det samme på nytt? undrer han.
Algoritmen som finner skjulte temaer
Analysemetoden forskerne har brukt, kan være nyttig langt utover akademia. Odden forteller at han har sett den brukt på politiske tekster og i spamfilter, til hjelp i litteraturanalyse i humaniora og i industrien til avdekking av feil.
Annonse
Når avisa New York Times anbefaler artikler for leserne, er det også basert på samme teknikk.
Det finnes mange metoder for å bruke maskinlæring til tekstanalyse. Den algoritmen UiO-forskerne har brukt, kalles latentDirichlet allocation, som går ut på å finne ukjente temaer i et sett av tekster.
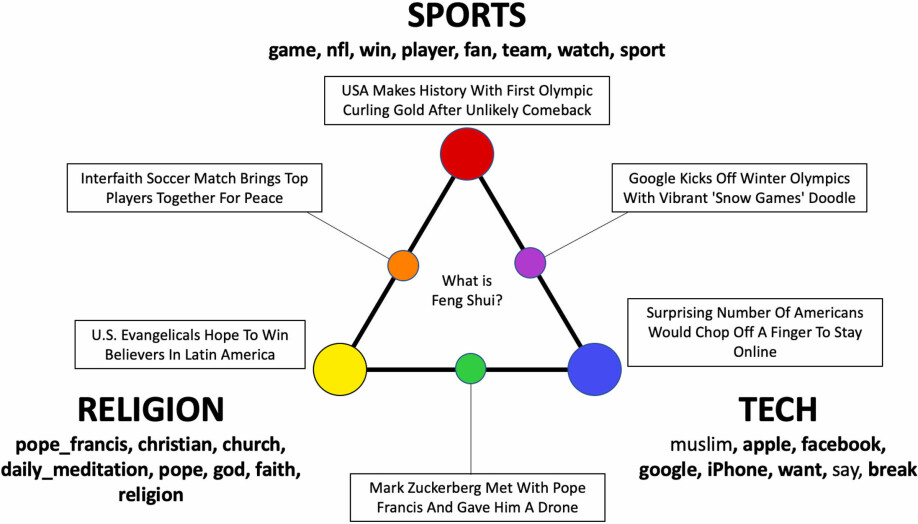
Odden og kollegene gjorde et forsøk med modellen hvor de lot den jobbe med 9000 overskrifter fra Huffington post og ba den sortere dem i tre temaer. Overskriftene var allerede sortert ut og kodet av et menneske til å tilhøre temaene sport, religion og teknologi, slik at det var mulig å teste modellen med dem.
Og ganske riktig, modellen putter overskrifter med ord som church, pope og faith i et tema og game, win og player i et annet. En setning som «Surprising number of Americans would chop off a finger to stay online» er plassert i tech-temaet, mens «Mark Zuckerberg met with pope Francis and gave him a drone» havner midt mellom religion og tech.
Den som bruker modellen må selv finne ut hva du vil kalle temaet, modellen gir deg kun et knippe ord.
Dataprogrammet sorterer avisoverskriftene som et knippe ord i tre temaer. Den som bruker modellen må selv finne ut hva temaene bør kalles, her sports, religion og tech.(Figur fra forskernes artikkel)
Erstatter ikke mennesker med fagkunnskap
Selv om automatisk analyse av tekst er et kraftig verktøy, krever det også kunnskap hos den som skal bruke det.
– Du må ha en idé om hva du leter etter, sier Tor Ole Odden.
For å få meningsfylte resultater må dataene blant annet renses for de mest brukte ordene. I artikler om forskning på fysikk-undervisning er det for eksempel uinteressant å ha med ordet «fysikk», siden alle forsker på nettopp det.
– Mennesker er de beste til å vurdere resultater og mening i automatiske tekstanalyser. Maskinmetodene kan forsterke det mennesker er i stand til å gjøre, men aldri erstatte oss, sier han.